Content Attributes
A modern enterprise data warehouse is a dynamic structure and consists of many different parts. Data warehouse components are based on many variables and are chosen according to the business needs of the enterprise. Most businesses use data warehouse solutions to provide quick access to constantly changing data. Give insights into consumer behavior and maintain a single. Unified repository for data collection across different geographical locations. Depending on the exact use-case of the data warehouse. Its constituent components are arranged uniquely to set up an architecture that can provide valuable insights and visualizations.
A typical enterprise data warehouse (EDW) consists of the following:
- Source Data
- Staging Table
- Information Delivery Systems
- Metadata Access Tools
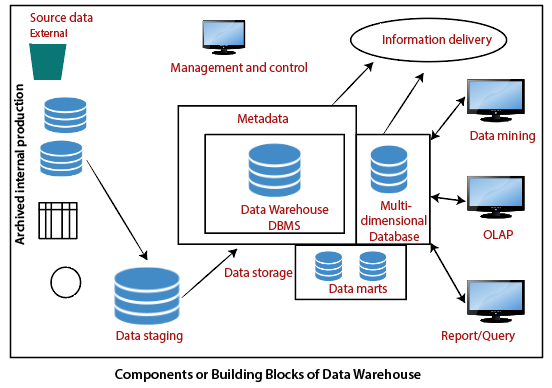
The data warehouse diagram above shows how different components of a data warehouse are linked to one another and arranged in the overall data warehouse architecture. In this blog, we will look at the purpose and functions of these constituent parts. The different factors that data professionals need to consider when setting up their warehouse architecture. And how these decisions affect the performance of a data warehouse.
Source Data
Source data in an enterprise may be divided according to the purpose it serves and how it is stored. Incoming data can therefore be divided into four main categories:
Production Data:
This refers to statistics on the enterprise’s production processes and operations. Typical production data tables might include stock tables, warehousing tables, inventory tables and shipment tables. Data analysts might choose different information segments from these tables to make up the production data relevant to their business insights.
Internal Data:
Internal data refers to departmental databases that include customer profiles, employee spreadsheets, performance reports and quantitative evaluations. This data might be aggregated in a data warehouse and used by HR departments to analyze the management and operations across various enterprise functions.
Archived Data:
This refers to historical data based on transactions and orders. While the primary purpose of a data warehouse is to analyze data in real-time. Historical data can provide useful insights about industry trends and assist managers in making more informed decisions.
External Data:
This is the data that comes from external sources such as other companies and organizations. Because of the diversity in sources, this data is usually unstructured and requires extensive mapping and transformation before being utilized in a data warehouse.
Staging Table
The purpose of a staging table in a data warehouse is to aggregate, clean and modify data. So that it becomes fit for use in a data warehouse. For example, as explained above, external data can be very unstructured and difficult to consolidate. A data warehouse architect might set up a staging table to correct the data and standardize its format before imported into a data warehouse. Three different processes occur on the source data in staging tables. As it forwarded to the storage components of the data warehouse. These are:
Data Extraction:
Each data source carefully examined – relevant data extracted and forwarded to the data warehouse for analysis.
Data Transformation:
Data transformation involves cleaning and correcting various data sources so that erroneous data does not contaminate the data warehouse. This can done by joining different data sources and standardizing data formats for each field.
Data Loading:
Finally, the staging table loads cleaned and structured data into the data warehouse. The initial load usually takes longer than the subsequent loads as it involves a more significant amount of data.
Information Delivery Systems
Information delivery systems automated and scheduled tools that propagate the information stored into the data warehouse into different destination systems, including spreadsheets, databases and OLAPs. This is the consumption component of the data warehouse. And it involves the utilization of data across the internet, the intranet, and the email networks of an organization.
These systems automated based on time intervals (daily, weekly, monthly) or by monitoring the occurrence of an event. Such as the arrival of incoming data or the successful completion of a transaction. These systems provide regularly updated information to data analysts across different geographical locations, according to their access rights and permissions.
Metadata
Metadata is perhaps one of the most significant components of a data warehouse; it defines and describes the incoming data and provides context to understand it better. Metadata is the primary building block of a data warehouse design. As it used in creating, updating, and maintaining the data warehouse. There are two main types of metadata that make up a data warehouse:
- Technical Metadata: Associated with development and code-related tasks that can help technical staff make sense of the data warehouse and modify it.
- Business Metadata: Consists of options and features that a non-technical user can easily implement.
Developers might develop a separate metadata repository that consists of a list of definitions to define and explain the data stored in the data warehouse.
Access Tools
Finally, in the consumption phase of the data warehouse. The consolidated information transferred to different front-end tools to use for various business use cases. These tools are generally code-free and eliminate the need for a database administrator working together with a technical data team. These tools can divided into four main categories:
- Query and Reporting Tools: These tools have features to help users navigate the data warehouse and quickly look for relevant information.
- Application Development Tools: These tools include features that integrate seamlessly with the data warehouse and perform predefined functions on the data to transform it.
- Data Mining Tools: Employ state-of-the-art AI methods, pattern and array recognition and statistical models to uncover insights from data.
- OLAP tools: Used to create a multi-tier data warehouse so it analysed from different perspectives.
Conclusion
The different components that make up a data warehouse play unique and vital functions. Therefore, it is imperative to understand what each element entails, how it relates to all the other components, and how it affects the performance and results derived from the data warehouse. Data warehouse architects need to make crucial decisions throughout the ETL pipeline to maximize their data warehouse’s potential and generate valuable insights from it.